
Video • Slides • Transcript below
I recently did a talk for the Swift User Group at Lyft, covering some of the challenges that come up when trying to perform image recognition on a mobile device. The talk was intended as an update to a talk I did last year: convolutional neural networks, swift and iOS 11, so if you have an extra half an hour you should watch that as well.
Below, I will loosely discuss the four main points.
Four Important Talking Points of Neural Networks
1. What to Study
2. Convolutional Neural Networks
3. Neural Network Architecture
4. Mobile Specific Architecture & Next Steps

1. What to Study (1:40)
There is some background on what you should study if you are interested in getting up to speed on neural networks in general. Very specifically, I would suggest you do some math review, complete the deeplearning.ai course and then tackle the fast.ai course from this year. After that you will be up to speed on pytorch (my current favorite deep learning framework) and ready to tackle real-world problems. Kaggle is great place to start!
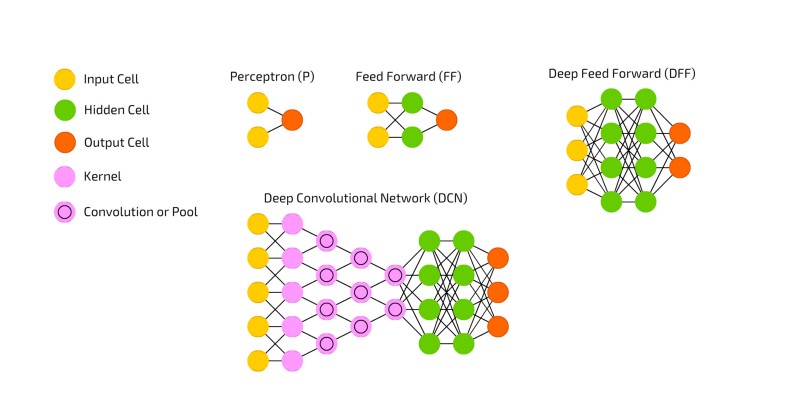 A heavily modified version of the neural network zoo
A heavily modified version of the neural network zoo
2. Convolutional Neural Networks (7:20)
At the beginning, we did an overview of how convolutional neural networks operate by looking at how perceptrons (single node neural networks) are built out of a classic machine learning algorithm, linear regression. From there, we looked at some different neural network architectures to try and explain the theory behind feed forward neural networks, the most common type in image recognition.

After that we did a quick overview of how convolutions work and looked at how to combine 3x3 striding and 2x2 maxpool convolutions with a feed forward network to produce a network called vggnet, which produced state of the art results in 2014. Finally, we looked at modifying our vgg network slightly to produce Resnets, which are a solid state of the art architecture that forms the building blocks of a number of modern techniques.
If you’re interested in different applications of Resnets, see my presentation solving go for a discussion of how the Alpha Go family of engines work.

3. Mobile Image Recognition (19:30)
We skipped through the neural network architectures I demoed in last year’s presentation (feed-forward neural network, vggnet, inception, resnet, mobilenets, yolo) and then looked at three new general image recognition architectures that I think you should add to your toolbox: densenet, darknet and unet. Densenet is network conceptually similar to resnet that achieves lower error rates, but at the cost of a more expensive multiply operator. Darknet is a tiny network, which I think is valuable conceptually. U-net is more oriented towards image segmentation, but as GPU’s get more and more RAM in the next few years I feel architectures like U-net, which can easily utilize extra variables, are going to become more common.
4. Mobile Specific Architectures & Next Steps (22:15)
We examined some mobile specific architectures, specifically squeezenet, mobilenet, shufflenet, senet, mobilenet v2 and finally nasnet mobile. Squeezenet is an network architecture from 2016 that achieved impressive results in only 5MB of ram. Shufflenet and Senet are interesting new ideas in the field. Mobilenet v2 is a solid update to the v1 architecture. Nasnet and other computer-generated (Amoebanet) architectures are only going to become more prevalent.
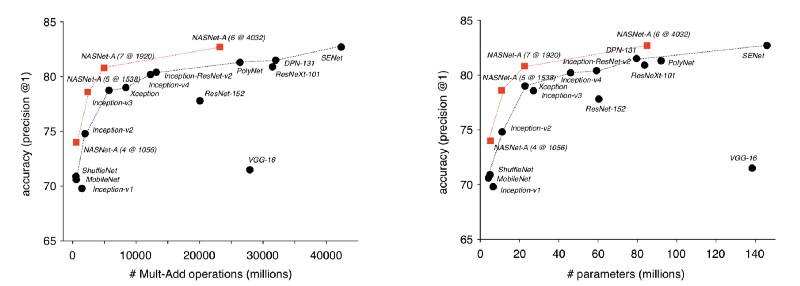 Comparison of size/complexity of different networks (higher and to the left is better)
Comparison of size/complexity of different networks (higher and to the left is better)
At the end (30:30), we discussed the upcoming pytorch conference and 1.0 release. Then we took a look at tensorflow on swift, which I am going to do a talk about next month! [UPDATE: read/watch here: tensorflow and swift]
You can download the slides from the talk here. Hope you enjoy it!
Transcript
My name is Brett Koonce. A little over a year ago, I did a talk on convolutional neural networks, Swift, and iOS 11 using this brand new API called CoreML. A lot has happened in the last year, and so this is kind of intended to be an update to that talk. So if you’re watching this on the internet, go find the other one first and much of this will make much more sense. I’d like to thank you all for showing up today. I’d like to thank Lyft for hosting us, and Kyle for pinging me randomly on the internet.
I’m going to explain some of the stuff I’ve been studying and give you a training pattern for if you want to get into neural networks, and how I think you should approach it. We’ll do a quick review of neural networks in general and convolutions and how they’re combined together to do image recognition. Then we’ll look very specifically at mobile image recognition, some different networks, stuff like that. Then at the end, I’ll hopefully leave you with some next steps on where to go from here.
I did a talk on this for about two hours at AltConf this year, and so the theme was like you’re entering a neural network Shaolin temple, so that will explain some of the pictures in the slideshow.
Self study
First, I think you need to know Python. I know this is a Swift meet up, but I think Python is the current language of data science. So if you’re going to start anywhere, I think you need to know Python. I put Roulette up here. I’d like you to know some basic statistics, but if I tell you to study statistics, you’ll end up reading some math book. Then you’ll end up trying to understand different distributions, and I think that’s the wrong way to approach things. If you can go to a roulette table and put a chip down and you know what the odds are of winning, then I think you actually have a good real-world understanding of statistics. In the same vein, I think you need to know the basics of calculus and linear algebra, but I don’t think you need to do a full blown college course on this stuff.
So just the six fundamental concepts of calculus, derivatives, limits, so on and so forth. The same thing for linear algebra — you don’t need a full-blown college linear algebra course, but I think you need to be thoroughly familiar of how to multiply matrixes and what’s going on there whenever that happens. There’s a course out there — Coursera, by Andrew NG. It’s kind of an academic course, but I think it’s the best place to get going. They have five lessons or so, and you pay $50 a month to get in. The second thing I like about this course is that they have pre-compiled notebooks. So if you’re not familiar with doing Unix software, you can play in their sandbox a whole bunch for free until you get the hang of working with virtual machines.
The Coursera course is based around Keras and Tensorflow, which is Google’s matrix math library. I’ve been doing a lot of PyTorch last year. I managed to take the fast.ai course earlier this year, and I would say if you wanted to take it up to the next step, just do the entire fast.ai course. It’s free, it’s online, it’s on youtube — the only price of entry you need is to get a virtual machine of some form. If you get a Paperspace machine for 50 cents an hour, you could be learning — I’d tell you to definitely put a few hundred hours into that. If you can go through those two courses, I think you’ll have a very solid understand for everything you need to know for neural networks, and you can basically go anywhere you want from there.
The next level above that — you’ll probably have to start reading papers or start looking at other people’s code. Practice. Kaggle is great for this. I would tell you not to do the latest and greatest Kaggle competitions, but maybe do the ones from a year ago. Then you can go out and look on the internet and see other people’s code and how they tackled these problems.
Then finally, I think you just need to get out into the real world. Everybody in this room probably has some problem or problem domain that they know better than anybody else. We’re all mobile programmers, but everybody brings something different to the table. So to me, what’s cool about neural networks is that basically anybody can become a domain expert in some oddball problem that only you understand. You don’t need a Ph.D. or any of this stuff that some people say. Even five years ago, dealing with all these libraries was a royal pain in the butt. But nowadays, basically, anybody can do it.
There are different ways of thinking about all this stuff. This is roughly how I like to organize it. At your basic level, you have your raw math, your CPU, or maybe universal Turing machines, something to that effect. The next level up would be a basic virtual machine. Coursera, Paperspace, running a Jupyter notebook. The GPU magic is kind of abstracted away, but you’re running on dedicated hardware. The next level up from that is cloud software. AWS, Google cloud, dealing with multiple machines and multiple devices to try to coordinate results. The next level up is mobile development. I put it way up here above the cloud, because a lot of times with the cloud, you can just cheat and throw more machines at a problem. Whereas if you’re on a mobile device, you have a very hard memory and speed constraints. Even if you can fit everything, you still need to run everything in a very throttled manner because you can’t use up all the power of the local device just to solve your particular problem.
The next level up is custom hardware. This is where a lot of people are super interested in right now. You have Google with their TPU, Nvidia with their Volta devices, there’s a lot of machine learning hardware startups that have been in stealth mode in the past year or two, so I think we’re going to start seeing a lot of custom hardware come to the market. This is sort of the very bleeding edge. But very broadly, I think we’re up here on level three. The more time you spend on these lower levels, the easier it will be to do stuff on a mobile device.
Machine learning
Machine learning. Very broadly speaking, there are three categories of machine learning. Today we’ll be talking about image recognition, which is a subset of supervised learning. Unsupervised learning is not very popular right now, but it’s mostly clustering algorithms, things like that. Reinforcement learning is becoming very popular, but I’ll talk about that a little bit at the end.
Obligatory XKCD comic. I find this one gets funnier the more machine learning you do.
Very broadly, we’re going to take an input — numbers, picture, audio, video, some form as a group of numbers. Then we have known data. To use the canonical example, we have cat pictures or dog pictures. Then we’re going to combine this data together with a bit of math to produce some sort of a magical black box. So we put in cat pictures, it says cat. We put in dog pictures, it says dog. In order to do this, we train the model and give it lots of pictures and give it feedback. That’s what the training loop is. Then finally at the end, we want to use it on an unknown dog picture, and it says dog.
Our goals can be thought of as being quality — just how accurate our model is. But in particular, on mobile devices, the size of our model, how many variables we’re using to do our math, how many megabytes of data we have to ship down the pipe, and the complexity — how many CPU cycles does our model take to run?
Linear aggression — you’ve probably seen this before, but it’s basically fitting a line to a group of points. Linear aggression comes up a lot because basically if we can think of all of our cat pictures on one side and dog pictures on the other side, if we can somehow magically learn to slope a line in between, that’s what’s called a perceptron which was the original invention of neural networks back in the 1950s or so. This is actually not as new of a field as you might think. There are some interesting things that you can do with single layer multi-node neural networks, but for most practical purposes, most real-world neural networks are two layers with multiple nodes. The simplest example is a feed-forward neural network. The data comes in, propagates all the way down to the end, no recursion. This is the Tensorflow.js MNIST layers example. Last year I did a whole bunch with the MNIST with a basic neural network, so I’m not going to go deeper into this one right now.
There’s a whole bunch of different neural networks out there. This is just a page showing some of the different variances. I’m going to start at the far top left corner, go over and then Z back to the very bottom with the deep convolutional neural network. So first we have our perceptron. Next, we have our feed-forward neural network. This is basically one input, one layer of nodes, one output. If we look at our deep feed-forward network over here, this is the basis of most neural network architectures. We do a bunch of stuff to come up with some sort of input, two layers of feed-forward neural network nodes, and a layer of output nodes…then we come down here to our bottom left corner, which is our full blown deep convolutional feed-forward neural network. So basically we take an input, run it through some convolutions, use two layers of green nodes — same as our deep feed-forward network up here, and finally, we do our output. So this is some variants of neural networks, but this is the structure of most of them.
The convolution part is the second part of the trick. Last year I said convolution was nothing more than matrix math. That’s a drastic simplification, I agree. But I think the basic concept that you need to get is that you put an image in, and you get a different image out. These are some different examples of smaller convolutions. The far one is a Gaussian. This one is a Sobel edge detector. You don’t need to know these, I’m just giving you some examples.
This is one I think you can wrap your head around. We take the input image, which is the far set of pixels. This convolution is just all ones, so it means that literally this output picture, the seven is nothing more than all those numbers added up together. So we do that one, we get an output, we have the convolution over one step, generate the next pixel, so on and so forth.
Two convolutions you need to know are these. There’s 3x3 striding, which breaks up an image into slightly smaller chunks. This is an excellent Github repository, which has information on this subject.
Maxpool — this one is easy to pick up. You just take a cluster of 16 pixels, take the largest one out of each group to make a smaller one. So we take a larger data set and we squash it down.
VGG
So if we take these two concepts, the striding and the 2x2 maxpool, we can combine them together to produce our first convolutional neural network. This one is called the vggnet. It’s structurally fairly easy to understand. We take an input image, we apply two 3x3 strides, a maxpool, two more 3x3 strides, maxpool, three 3x3 strides, maxpool, three 3x3 strides, maxpool, three 3x3 strides, maxpool…for our final fully collected layers, this has 4000 nodes on each layer. Finally, we have an output layer to link up to our results. This network was cutting edge in 2014. It’s kind of viewed as being like a dinosaur by modern standards because it’s extremely data hungry and it uses a lot of CPU. But conceptually, from taking a basic image, convoluting it down and adding the two neural network layers and doing the output, I think this is probably the best way to understand the basics of a convolutional neural network.
Resnet
Last year I talked about Resnet for about 10 seconds, which really wasn’t fair to Resnets so I’m going to spend a little bit more time on it here. If you look at this chart, the far left graph is the vgg 19, which is the cousin of vgg 16 that we were just looking at. It just adds a couple more 3x3 strides in the lower layers. The basic problem that the vgg network has is that the final result has to go through all the layers if you will. So even if say the second layer up here gets the right answer, it still has to pass through each layer all the way down. So a little bit error up here becomes a little error here, and a little more, so on and so forth until it finally gets to the end. Because of this, the vgg is actually about as big of a real-world convolutional network as you’ll actually ever see. They were pushing the limits of what was possible.
So a team from Microsoft came up with residual networks. The basic idea is that we have these layers that are now strongly connected. This solid dark line can be thought of as one large block. Then there are these three dotted parts down here. What happens is that the neural network can learn — that’s what the neural network learns whenever it does its training step. So say the first layer actually recognizes the object, basically the neural network can learn and just short circuit the whole network. This means resnets can handle large amounts of noise. That’s what makes them very powerful. The second trick that the resnets bring to the table is that they use this average pooling step at the end. Instead of doing the fully connected neural network layers, we do the average pool step. It’s cheaper in terms of CPU cycles, and it’s much easier to evaluate. So as a result, these are literally an order of magnitude faster and easier to build, and the beauty of this Resnet approach is basically you can keep on adding more and more layers until you get something that actually solves your problem. So this is a 34 layer resnet, but you can take this network and stack it up five times to get 150 layer network, and that’s a fairly solid approach. We’ll see that in a bit. I did a talk earlier in the year on AlphaGo versus AlphaGo Zero. One of the big changes that they made between the two versions of the engine was simply going from a CNN approach to a resnet style approach between AlphaGo and AlphaGo Zero. Conceptually, we might imagine these pink blocks right here as being a single residual block within the AlphaGo thing, then it has, say, 40 of these blocks, and that was sufficient plus a bunch of GPU time to solve a game of Go. So resnets, if you learn any one thing from this for image recognition, just say resnets and you’ll probably have a good example. Apple has a nice demo of this in TuriCreate. If you’re wanting to build one on your own, you can download TuriCreate. I’ll talk more about it in a second, but that’s another good way to get going.
Hopefully, by now I’ve covered the basics of convolutional networks and how they’re built. From here, we’re going to go into mobile-specific networks. Basically, we’re going to start adding more and more complexity with the goal of reducing the amount of CPU cycles that we’re doing in our networks and increasing our accuracy. So everything from here is going to get more complicated for more marginal improvements.
Last year I demoed a basic neural network with MNIST, vgg, inception network, resnet, and then mobile nets as well as YOLO, but that’s an object recognition network. I was excited about mobilenets, which are everywhere now, so I think I did alright there. Three more general image recognition networks I would suggest you look at — the first is Densenet. If you understand resnet, resnet actually uses an add operation in order to combine the layers. So we take that add operation and convert it to a multiply operation, you have densenet. This has some interesting properties for how error propagates through the layers and reduces the error, but also makes the whole network more computationally extensive. Darknet is an image recognition network from the guy who created Yolo. What I like about this one is that if you look at the code implementation of it, it’s about 17 lines of code or so. You can literally just stare at it and hopefully obtain enlightenment. If you look at the fast.ai sources, Jeremy has an implementation of it in there.
Unet is another neural network architecture. It’s probably better for doing image segmentation if that’s what you’re wanting to do. I think it’s interesting because I think that’s probably where things are going in the future. It’s a network that you can throw more and more ram at it, and it will just expand to fill that up. So as pictures and images get bigger, I think this approach is where a lot of things are going to end up.
Mobile-Specific Models
Now we’re going to look at a bunch of different mobile networks. Squeezenet is one I should have talked about last year, but I didn’t. We’ll look at mobilenets again, and three from last year — shufflenet, senet, mobilenets version 2, and finally nasnet mobile.
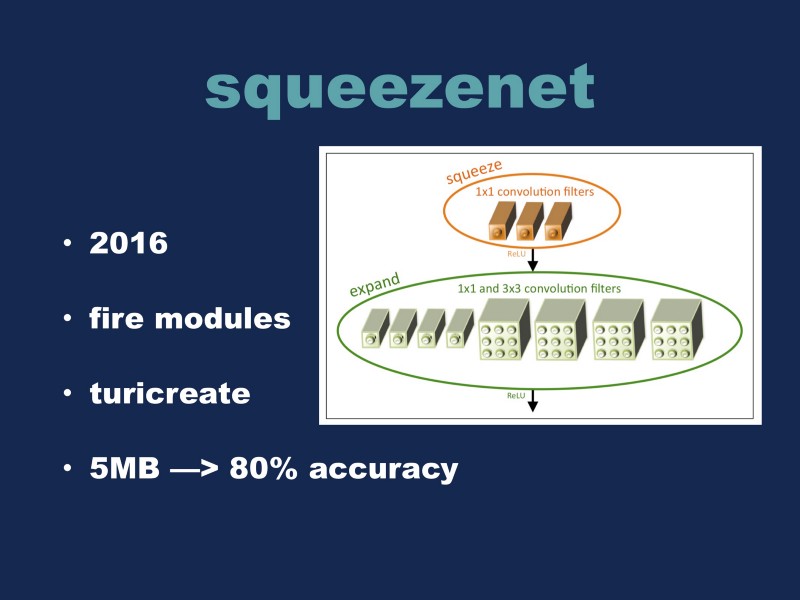
Squeezenet is from 2016. It has the concept of these fire modules. Basically, they squeeze the entire network down literally, and they expand to have the secondary layers. The whole network is a combination of 8 of these modules. Using this approach, they were able to reduce the amount of variables needed to make an image recognition network way down. So this one, there’s a 5mb version which can achieve about 80% accuracy on imagenet, which is pretty good. They even made another version of it where they took that network and lobotomized it slightly to get it down to half a megabyte, but it still had decent accuracy. It also runs pretty fast. This one is in TuriCreate. TuriCreate is a tool that Apple released in February of this year, I believe. They took some of the good ideas from Keras and Scikit-Learn with their CoreML tools from last year and made a unified tool. If you’re doing stuff for Swift and you’re only targeting iOS, I would highly recommend you take a look at TuriCreate because I think that’s the best way to get going.
I talked a bit about mobilenets last year. It makes heavy use of the concept called depthwise separable convolutions. Google released a new version of the Tensorflow library. I demoed this with Tensorflow proper last year, but now they have this Tensorflow Lite set of libraries which are more targeted for mobile devices. What’s cool about Tensorflow Lite is that there is an android version as well, so if you need to be cross-platform, I think that’s my current recommendation for what you should be studying. With iOS 12, Apple released CreateML. This is built on top of mobilenets. They have this drag and drop GUI for putting all your images into folders and dropping them there and hitting the run button — you should check that out. But if you’re wanting to do something more complicated, I would advise you to go to TuriCreate.
This is shufflenet. This is a paper that came out late in the summer of last year. It’s by a research group that’s not particularly well known or famous so I don’t think it got as much press as the other stuff, but they had some very interesting ideas in it. They introduced this channel shuffling operator which they then add to this residual network style approach. It makes heavy use of pointwise depth convolutions, which is a similar concept to the mobilenets, but slightly different. They were able to achieve similar performance, slightly higher performance than mobilenets at roughly similar cost in terms of CPU cycles and complexity. Here’s a nice medium article you can read if you want to learn more about that.
Senet — this is a paper to come out of the group that developed vgg. The Oxford visual geometry group — the original version was last year, and it won the ICLR image recognition contest for that year. They had finally gotten the accuracy of these networks to be up to around 97%, which is pretty impressive considering where it was at just a few years ago. I would describe it as taking the concepts of squeezenet, but then using something similar to densenet to combine the insides of the layers, and then adding the group convolution idea on top. They re-released a new version of this thing. I wouldn’t recommend this for day to day use, but I think this is one of the ones that you should look into. The people that did mobilenets, went from mobilenets and they basically did a version upgrade to it. It’s slightly more efficient, slightly better performance, and so on. They took the blocks and went from two-layer blocks to three-layer blocks with this expansion layer trick here. My friend Matthias wrote a very nice write up on the whole thing, so if you want to get into it, go look at that. This is what we’ve been using for doing our projects. If you’re looking for what’s cutting edge today, this is your best bet. There’s also Tensorflow Lite’s implementation on the Github platform as well.
All these people are doing all this stuff, trying to build all these networks, and Google said, “Why don’t we just put some machines in charge of doing this?” This is nasnet, network architecture search. They basically wrote a computer program to go out and search through all these different types of architectures, and just come up with the best possible combinations. So if you look at the actual nasnet architecture — I don’t think you need to learn it, but it’s literally just this Frankenstein monster of eight different concepts, combined together by a machine in a way that makes sense to a machine, but no Ph.D. student would have ever figured that out. By running this whole search algorithm, they were able to significantly advance the state of the art in the field.
We had this little black dot over here, this is the original vgg network we were looking at. If you go up semi-diagonally, that’s a resnet 152, which would be the larger version of the resnet 34 that we looked at. This black line would be roughly the state of the art for the last few years. This red line is basically what the computers were able to achieve, given an ungodly amount of GPU time. Out of the nasnet research, Google did a couple of papers where they came up with different methods to do these architecture searches. They created a tool called AutoML that they’re pushing now. The idea is that you upload your data, ask for the best version, you walk away and come back and it’s there.
Earlier this year, they took that same nas approach and combined it with genetic algorithms to produce another group of architectures, of which one was called amoebanet. I took the fast.ai course and we entered this competition against a bunch of different people, but Google came in first ahead of us with their amoebanet entry. I think this is where the future of everything is going. It’ll be more like humans trying to come up with clever new ideas for machines to experiment with. I don’t think you need to know this, but this is where things are at right now.
The future
Now we’ll just go into where I think you should be looking next and the future of all this stuff. I’ve done a lot of Pytorch this year, I like it a lot. But the process of getting a Pytorch prototype to an actual thing that you can run on your mobile device is still pretty tricky, I’d say it’s not terribly user-friendly. They’ve invented this tool called Onnx as this universal gateway in between all these different platforms. On October 2nd they’re going to have some sort of conference where they are supposedly going to release this. My guess is that they’re going to push Caffe, or rather Caffe 2 as being their universal solution. So you’ll build your model in Pytorch, then Caffe 2 will run it on the device for you, and Onnx will be the middle layer that keeps everything happy. There are tools for various other platforms to convert their stuff to Onnx. The interesting player to me here is MXnet, which is the Amazon project. I think they’re kind of a dark horse out there and they may yet try to make a big play in this field. But you can take Pytorch, convert it to Onnx, and convert it to CoreML files, but I would not advise that for day to day use at this point in time right now. Hopefully, soon that will change.
The other big thing on the horizon is Tensorflow and Swift. About a year ago, Eager Execution came into Tensorflow. If you’re familiar with the two platforms, they’ve taken one of the key concepts of Pytorch and brought it to Tensorflow. The last year has been them writing more and more things into this Eager Execution style model. They’ve officially put out the roadmap for Tensorflow 2, so that’s coming. The thing that’s interesting to me is that Chris Lattner is working on a project at Google — that’s hopefully going to make heavy use of Swift’s type safety, plus LLVM to bridge between these two worlds. Tensorflow as it currently exists is a lot of brittle C++ code, and generating optimized code from old devices is difficult. My hope is the promise of openCL from a few years ago will come to allow you to generate stuff for your mobile devices. If you’re interested in more than this, there’s a nice youtube presentation on this at the TF Dev conference in May of this year. They demoed doing the TPUs and everything using Swift, so you can look at that. I’m going to hopefully do a talk on this where we go absurdly deep in a couple months. (Update: go here!)
If you’ve got convolutional neural networks down, then I think you should learn recurrent neural networks. GANs and reinforcement learning are super popular right now. I know lots of people are interested in them, I think there’s money to be made there, but I don’t have a clue how to do it. It’s very much, to steal from the underwear gnomes: Gan/RL > ??? > Profit!
[underwear gnomes picture]
I think language models are very interesting. This computer vision stuff has a ton of people who are putting a ton of cycles into it, but you can generate language models fairly easily. I think that’s probably going to be the next big thing in a couple years.
That’s basically all I’ve got for convolutional neural networks and Swift, so I’ll take some questions.
Q&A
Hey, I’m Steven. Thanks so much, that was good. I was reading about someone talking about iOS 12 and being able to use transfer learning for a model that was maybe built in the Photos app so that their model in their app was really small. Can you talk a little bit about what that means, and what’s new in iOS 12?
Sure. Transfer learning is when you take a network trained on one problem and apply it to something else. A classical example is you take a network that’s trained on this image net data set which is like 1.2 million things, and you can easily retrain the model to solve problems. It’s trained on cats and dogs. You put it on your friend’s face, and technically under the hood it’s saying, “This person looks 70% like a golden retriever, plus 25% of a labrador, versus this other person who looks…” That’s kind of how it actually works. It actually works really well in practice. TuriCreate does that. The next level up is Apple basically embedding some models on devices, and they can ship down the differential in order to reduce the amount of data that’s being transferred.
Lattner’s working a lot on Tensorflow at Google, and he said that Swift is going to be the first class language for Tensorflow. If you wanted to get into Tensorflow, do you think you could just do Swift? Or would you still want to beef up on Python?
Tensorflow itself is like a bunch of C++ libraries. Google’s had to embed all these various C++ accelerated libraries, so they have like Boost and XLA and a bunch of random things like that in there. So coding pure native Tensorflow is not super fun. Then Keras exists, which is just basically a Python high-level wrapper. A lot of people code in Keras because it’s slick and it’s easy, but ultimately if you want to do anything that’s outside of the Keras garden, then all of a sudden you’re into the weeds with C++. So with Swift, I believe their vision is to unify these two worlds. They want to use just one programming language across both things. I think the vision is good, but it’s going to take them a little while to get there. I think it’s definitely the future. As for where you would want to start today, I still think you should do all this other stuff. The concepts from all this Python stuff will definitely transfer over to the Swift world far faster than all these tools will be rewritten into Swift in say, the next year or two.
CNN Network papers
General:
Mobile: