
Video • Slides
A big thanks to Jaim Zuber for introducing me!
Overview of Talk (0:22)
Hello, thank you all for coming. Thanks to AltConf for having me. Today we’re going to talk about Swift for TensorFlow. Very broadly, I spent the past few months getting up to speed on all of this. I’ve decided this is how I’m going to be doing things going forward. The purpose of my presentation is to convince you to do the same. Towards that end, we’ll ask the question of why you would want to combine these two tools and how we got here. Then we’ll zoom out a little bit and look at where I think things are going down the road. Then we’ll look at what we, Swift iOS programmers, or perhaps more broadly mobile programmers in general, bring to the table. Then I’ll show you what I think the best way to get started with this whole thing is, and then we’ll do a quick recap.
I usually put comics in my presentations. Today, I have a bunch of stuff from Calvin & Hobbes. If you don’t like Calvin & Hobbes, I feel sorry for you.
The Importance of Using TensorFlow and GPUs (1:32)
Why TensorFlow? The broader question you can spend a little bit more time on is, why GPUs? Your computer has a perfectly good CPU in it, so why are we using your video card to do math? I think if you look back at the history of computing and you go back into the 80s or so, and you look at Cray, he was convinced the future of supercomputing was something called Vector Processing. You had this concept of SIMD, single instruction, multiple data. If you look at the current generation of NVIDIA RTX video cards, they all do ray tracing. You might think of each pixel on the screen as having a little bitty ray-tracing program, and then your whole view or scene that you’re seeing is a large collection of data. So then for every single pixel, 4,000 across by 2,000 down, you are literally running a separate thread, in order to render what that particular pixel is seeing every single frame. So millions of threads are being executed every second, and it’s very much the same concept, I think if you were to go back in time and show it to Seymour Cray. These cores in these video cards — it’s easy to parallelize this approach so you can throw lots of cores at these problems. So modern video cards have something like 5,000 cores, and even 10,000 core designs are currently being discussed. So, this is an approach that scales. The cores are slower, but not as powerful, but there’s a lot of them.
The second piece of the puzzle is the GPU memory sub-system. If you study the history of high-performance computing, a lot of it is actually less about processors and more about how they talk together. So the memory sub-system inside your video card is literally an order of magnitude faster than the RAM in your computer. So, this is another reason why we want to do things on a video card.
So, roughly a decade ago, doing things on a video card became remotely feasible, and people started trying to build these frameworks in order to work with this stuff. Literally, there were a dozen frameworks that exploded. Some from academia, some from the industry, but out of them all, TensorFlow has become the 600 lb. gorilla of this ecosystem, we’ll say. TensorFlow itself, proper, is written in C++, which is user-friendly, but it’s very picky about who its friends are. One of the first things that was invented for TensorFlow was Keras, which was sort of this high-level Python wrapper to make dealing with it a lot less painful. Google has sort of embraced Keras, and it’s become kind of part of the whole thing. The last year or two has been them trying to find a happy medium between these two ecosystems.
Why Google has Succeeded (4:32)
Part of the reason why I think Google has been able to succeed on this front is because they have what I would call an iron triangle. Machine learning is extremely important to Google. It literally drives their bottom line over there, so they’re able to throw a lot of resources at all this. They have this whole Google Brain Team that’s always publishing interesting new research, and alongside their research, they always publish new models in TensorFlow. This makes their whole ecosystem very sticky because people are literally every day downloading their stuff and trying it out. Then, the third and final thing that people are less aware of is that a lot of this machine learning stuff breaks with some regularity. So, Google has a whole army of engineers running around in the background hitting on things with hammers, in order to create this illusion that it’s all perfectly smooth and seamless. There are other companies in this space — they may have resources and engineering, but they don’t necessarily do the research. They have two of these three things, but Google is the one that has literally a lock on each of these things. That’s why they’re so successful.
Reasons for Using Swift (5:41)
Why Swift? Hopefully, I don’t have to evangelize Swift here. Swift came out five years ago. This year to me has been the year where my old crufty objective C programmer friends will come up to me and start saying, “You know, I think there might be something to this whole Swift thing after all.” So at one point, it was a company called NeXTSTEP. They wanted to write an operating system, and they wanted to use a programming language called Smalltalk. Smalltalk wasn’t very fast, so they wrote a set of bindings for the C language to bring the Smalltalk ideas to C, that was called Objective-C. In order to do so, they then forked the compiler called GCC out of the free software foundation. I’ll try to reduce down this subject very quickly, but we’ll say that RMS, one of the key people in the free software foundation, a founder, felt that the compilers were one of the key technologies of the opensource movement — and so he made sure that they actively resisted outside interference, we’ll say. As a result, I think they created an opportunity for another opensource compiler to come into this whole ecosystem, which is what happened whenever Apple threw their weight behind LLVM out of the University of Illinois with Chris Lattner. If you think of your program as being like a collection of instructions, you might make a list of all the spots where variables are accessed, and by extension, you can make a graph. Then you can go to this graph, go before the very first instruction, put a malloc (call) and after the last one, put a free (call). This is kind of the basic idea of how automatic reference counting works, which is one of the first technologies that LLVM introduced into the C world. In the same vein, you can do this sort of graph traversal trick with closures, and so they introduced thread safety checks there for a while. The problem with this though is they were retrofitting these changes on top of C, and there’s a limit to how far they can push this technology. So then four or five years ago, they announced Swift which brought full blown functional programming into the iOS ecosystem.
I would argue that Swift is in many ways not a revolutionary language. It’s a fairly pragmatic language that sort of takes ideas from many other programming languages and puts them into a coherent unified whole. It’s designed to work side by side with Objective-C, it doesn’t really force you to completely change your paradigms — but I think this is part of why it’s been so successful. It’s allowed imperative programmers like myself to look at it and squint and say, “This looks reasonably similar to what I’m used to.” But then I think about six months to a year in, you start to realize that there’s something a little bit different here. For me, personally, I went back at one point — I was coding on a Swift project for a little bit, and I started going back and messing with some old Objective-C code that I hadn’t touched in a while. I started staring at all this memory code and all this various stuff, and I realized I haven’t even thought about this for a while. To me, that’s what’s cool about Swift. There’s a whole new generation of programmers out here who have grown up using Swift, and they don’t even really have to understand how memory management or any of this stuff works under the hood. This whole history that they’re not even aware of. So, I think Swift is cool in that it’s a functional programming gateway, but it’s been snuck on the whole ecosystem.
Combining TensorFlow and Swift (9:40)
So why have we combined these two? [To look at a couple of different examples] Pytorch has historically gone straight from Pytorch into Cuda, so it’s compiled directly to Nvidia. The big push this year for Pytorch, which is another machine learning framework, is they are adding this Pytorch IR and in this JIT compilation layer. So basically, they’re adding an intermediate layer in between their Pytorch and the actual output. Another language, JavaScript — the big push this year has been, “We’re going to start doing JavaScript that’s going to compile down to assembly.” In order to make this even possible, the JavaScript world has been really heavily embracing type safety, so they’re sort of bolting these functional programming paradigms on top of their existing programming language.
So Google is basically saying, “We’re going to restart the whole project, and we’re going to build it from the bottom up on top of a clean, functional programming language, which is Swift, and then on top of that, we’ll be able to do all of these cool tricks. Julia is another machine learning programming language, and they’re piggybacking on top of all this. But for TensorFlow 2, the big push this year is to get everything over to XLA. Historically, TensorFlow has not had a unified linear algebra system, and so Google is saying, “Okay, we’re just going to do everything one way. It may or may not be the right way, but then at least any optimizations we get will be applied to the whole ecosystem.” So the second part of Swift for TensorFlow is this MLIR part, which is the LLVM portion of all this. Essentially, we take the machine learning code, they’ll be able to convert into MLIR, and then you’ll be able to output it into whatever device you would like. So, the practical short-term upshot of this is that you’ll be able to write code once and generate optimized run times for CPUs, GPUs, and TPUs. But now there are phones, people are starting to want to build things for phones. This is less of a concern over here in the iOS world, but Android — literally there are dozens of manufacturers who are wanting to bring different neural network architectures into play. So, this gives them a unified system for that. Then another thing that is cool is that people are literally building new hardware to do machine learning with, and so basically, if you can write a way to get from MLIR to your hardware code, then you can bring the whole TensorFlow ecosystem to your device, which is a pretty cool ability.
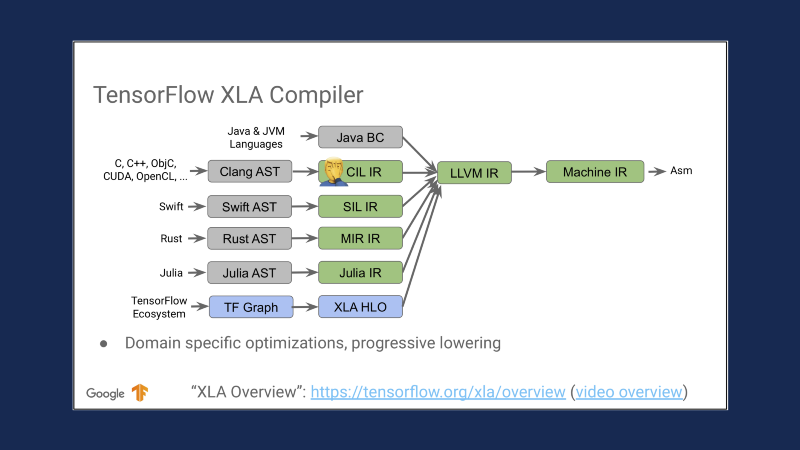
This is a slide from Chris Lattner’s MLIR presentation from a few months ago. I think it sort of illustrates how all these worlds are coming together. We have various different front-end languages generating intermediate languages, LLVM here, and then at the end, you can imagine it branching back out to in theory whatever device you would like.

The Future of Development (12:46)
Now let’s look at where I think things are going. The first big story I think has been cloud computing in general. We used to treat computers as being discrete hardware units, but in the last few years, or decade or so, we’re increasingly just thinking of them as being computing resources. You might say, “I need this amount of RAM, this amount of CPU, this amount of disk space,” and a cloud provider can say, “Okay, here’s your machine. Go off and do whatever you would like with it.”
But hardware marches on. Every day, computing is technically getting slightly cheaper, we’ll say. We might think of it as eventually, as the price of computer cycles approaches 0, the amount of resources available to a developer are going to approach infinity. By extension, all of these tools can, in theory, provide you infinite CPUs, infinite GPUs, data, and network access. So the question is, what are we going to do with all of this? The short answer is, nobody really knows. All of these platforms are basically saying, “We can get you these tools.” But everybody is really fighting over, “how do we make this easier for developers?” Because they’re expecting developers to actually figure out how to use them. So right now, I think we’re seeing this whole proliferation of tools to deal with various problems at scale. To use an example, we’ll take Kubernetes as a technology, you might say, “Well, how do you manage a cluster of a thousand computers?” The Kubernetes people say, “Well, you don’t. You manage a cluster of ten computers, then you have your cluster of ten computers manage your cluster of a thousand computers.”
The next trend that we’ve seen a lot of is just big data and computing in general. The basic observation is that having lots of data really simplifies algorithm design and doing this deep learning stuff. So if you have a thousand data points, you need to get more data. If you have a million data points, you might be able to do some feature engineering on top in order to produce results. But if you have a billion data points, all of a sudden, your outliers become entire categories into themselves. Then all of a sudden, you don’t have to really use sophisticated approaches — you can just throw more and more machines at it.
The general paradigm though I would say in the machine learning world is that we have lots and lots of single-threaded jobs. It’s easy to take one particular job and run it a hundred times on a cluster or scale it, run it across a hundred machines, but it’s difficult to take one job and scale it up to run on, let’s say a hundred GPUs at once. So a lot of the interesting research to me right now is in this area, where people are finding ways to break problems apart to where they can be parallelized. But in general, I would say not to fear the cloud. Many people make a big deal about having large amounts of resources, but I would say that the key is just to know the right path. If you do that, you can keep up with these people and their fancy clusters.
About AI (16:18)
So next, let me ask you the question — what is AI? At one point in time, the computer scientist people got tired of this question, so they said that reinforcement learning is a subset of deep learning, which is a subset of machine learning, which is a subset of AI, which is a subset of things humans can do, which is a subset of the universe. Thus solving the problem once and for all.
I’m not going to argue the whole ontology of this, but this whole idea of defining intelligence as something humans can or cannot do has always seemed to be a little bit suspect. Likewise, defining things in terms of what a computer can or cannot do has always been moving goalposts. Computers can’t play chess. Okay, well computers can play chess, but they can’t play Go. Okay, well computers can play Go, but they have to learn from humans. Okay, well computers can learn Go from first principles, but they’ll never be able to play StarCraft.
Every year, the pace goes on. Broadly, what we want to do is say that something hard to do is AI. But we don’t really know a good way to say that. On the flip side, we might say that something not hard to do is not AI. So does anybody know what 6 x 7 is? Right, 42. And does anybody know what 42 to the 42nd power is? (~1.5e68) Nobody in this room can calculate this number, right? So does my phone have AI? No. I’m confident you all are computer programmers — if you went off with a machine, you could find the right answer. But you couldn’t actually do it by hand. So, I think if you look at your answer — if I say, “Is this AI?” You would say, “That’s not AI, that’s just math.”
The thing is if you start talking about AI — if I stand up here and talk about AI, AI in the future, where I think AI is going, it kind of sounds mysterious and grandiose. Whereas, if I talk about math, it becomes a little more boring or even obvious. We can solve big math problems. In the future, I think we’ll be able to solve bigger ones. We can take some of these bigger problems, and we’ll be able to figure out ways to make them smaller to where we can run them on a phone. There are entire areas of math we haven’t even figured out yet, and there might be ways of using areas of math we haven’t figured out yet to solve problems in math that we haven’t even found yet.
Conceptually we can say, once we solve a problem, we can then reduce it down to the smallest possible algorithm or data, so to speak. From there, we take this combination and we move it as close to the user as possible in order to reduce latency. This can be thought of even broadly than machine learning, for example. Google builds data centers all around the world to host their webpages. The reason for this is that they know that if you get your results 1% faster, you’re 1% more likely to use their search engine, which means they make 1% more money. Google programs Gmail in JavaScript — it’s not because the Google engineers have a great love for JavaScript, it’s because that’s the best way to produce an interactive app that runs on your desktop.
So, I think long term, ultimately, people wake up with their mobile phones in the morning and they go to sleep with them — so the mobile phone is always going to remain the ultimate platform to solve problems whenever, wherever, and however the user wants.
Mobile Applications and Developers (20:32)
Which brings us to mobile developers. Very broadly, I think one of the basic things about developing for mobile apps is that we have all these limitations. We don’t have as powerful of computers, we don’t have as powerful of GPUs, we don’t have as much RAM as everybody else. But I think in many ways, these limits make us more creative.
We build entire worlds with tiny amounts of resources. We work with hardware directly, oftentimes going right down to the machine level. So, we can combine these tricks together to create the illusion of performance. My favorite example of this is Instagram. You take a picture, you spend a minute figuring out the right emoji to put on there, and then you hit upload and it goes up to the internet just like that. I’ve watched many people do this, and to them, it’s very simple. That button hits upload, and there it is.
But as somebody that actually does this programming, you say, “Wait a second, that picture is 3mb and my internet connection has only got this much bandwidth, so it had to have taken at least 5 seconds to upload. How did that work?” The short answer is that Instagram doesn’t actually upload the picture whenever you hit the upload button. It started uploading the picture ten seconds ago, whenever you selected it from the camera roll.
So, these are the sort of games that we can play to make the machines seem way more powerful than it actually is. To me, that’s what’s cool about being a mobile developer. If you understand the magic under the hood, you can play these games in order to create these illusions. That’s one of the cool things that we can bring into this whole world. If you understand how things actually work, then you can hide them back away again.
Converting Existing Cloud & Desktop to Mobile (22:30)
The second big thing that we can do is that we don’t really need to re-invent the wheel. We can take existing cloud and desktop solutions and simply convert them to mobile. So, two days ago on Monday, they did the WWDC keynote, and Apple did two neural network demonstrations during their presentation. They just didn’t call them that, but let’s do them right here again just to see them.
So, here’s the first demo they did: pose detection. They did this with the little robots halfway through, if you saw it. Here’s the second demo they did, where they were doing real-time scene segmentation on a person, and then compositing them into a 3D world. Both of these demos right here that I’m showing you are JavaScript. The cutting edge part of what Apple did with them wasn’t building them, or anything like that. It was simply making them run fast and making them run on a phone. That’s something that any of us can do. Those demos have existed on the internet for literally a year now. Any of you could have found them and been working on converting them to mobile.
To me, this is what we should be doing — finding these things before the big people do it, and do it ourselves. The second thing I would love for us to do is to re-examine the paradigms. Many of this stuff exists a certain way because it has a legacy code aspect, and we have this opportunity now to rebuild everything from scratch and rethink how everything is done.
Mastering Machine Learning (24:28)
So, what tools do you need in order to succeed with machine learning? I think functional programming is going to be one of the key factors to all of this. But you have this already if you’re doing Swift, so I put a star up here. I think you need the basics of calculus, but enough that you’re not afraid whenever people use terms like derivatives and integrals — I don’t really think you need the full blow college course in this stuff. In the same vein, I think you need some linear algebra. You need to be thoroughly familiar with how matrices get multiplied, but you don’t need to understand Jacobian forms work.
Another important thing I think you need is an intuition about users and how they think. Back to the same thing — if you’re already developing apps for mobile, you have this already. I think you need to understand real-world statistics, which is less probability distributions and more, “Okay, this computer gave me this percentage point. How valid is this number?” My usual example for this is roulette, but roulette is a little bit boring. So if you want to know all of statistics, just learn how to play a game called Craps. That will teach you a lot.
Then finally, I think you need a willingness to experiment — most of the stuff in our world, Apple and people have developed all these tools down to where you can change a variable and hit run, and see the results instantly. Whereas if you go back into this machine learning world, it’s very much hit a button, come back in an hour, or sometimes in a day. Towards this end, I think you need patience. But if you’ve ever dealt with the app store review process, you have that already as well.
Tools to Get Started (26:14)
Now I’ll try to give you a template for how to get started. Many people in this space will say, “Download this API. Ten lines of code, change three things here, add your data here,” and they promise you quick results. I’m not going to do that. It has taken me a while to get good at this, and I don’t expect it will be any different for any of you. On the flip side, I think if you come into this stuff with the mentality that it’s going to take a while, you won’t expect instantaneous results. If you do a little bit once a week or once a month even, over the course of a year, I think you can get up to speed with this stuff.
Jupyter Notebook (26:57)
The first important trick I think you need to know is Jupyter Notebook — this is similar to XCode playgrounds, but they run on the web. Google has their own version of Jupyter called Google Colab, and it runs both Python and Swift kernels. You can get started doing deep learning in the cloud for free without really needing to understand how all this stuff works. So, let’s do a quick demo of that now.
This is just a basic Python running in Google Colab instance. I’ll let it catch up… We’re literally typing code in here and it’s going up to the cloud, running it there, and then we’re printing out the results and it’s coming back down. A couple of years ago, I did a talk on how to put mobile networks on mobile devices, so I did a demo using the MNIST dataset. So, what we’ll do now is just copy-paste this demo off the internet and run it in our Google Colab. So, here it is running, … if we give it a few seconds — now we’ve built a simple computer vision model in order to do the MNIST data set. Like I said, this is running all in the cloud on GPU, it’s all abstracted away, but you don’t have to actually understand how all the nuts and bolts work to keep going.
Then, this is a trick many people have not seen, but you can open up notebooks within this thing. So, you can go to GitHub and search for fast.ai. They did a new version of this course last fall. You can do all of these fast.ai demos just using the web editor, and these Colab codebooks and streaming the content off of YouTube. So, you can bootstrap yourself for free, or the cost of a Google account.
I think this is a super cool trick that everybody should at least be aware of. It’s also nice if you find random code off of the internet because you can just run it and they can worry about the security implications for you. Here’s the actual code that I’m running on GitHub. I think Google’s vision long term for all this stuff is that a lot of data scientists will be able to do stuff just using Colab, but I think for the here and now, you’re going to have to do some command line stuff.
The Fast AI Course (31:54)
I took the fast AI course again this spring and they rebuilt the principles of deep learning from scratch. The last two lessons were taught by Chris Lattner, and they did all this stuff. Effectively you have Jeremy Howard, who is extremely good at deep learning, and you have Chris Lattner, who is extremely good at Swift, working together to give you the simplest possible path to get going with Swift for TensorFlow.
Towards that end, we’ll run the Notebook from the fast AI 2019 deep learning course. Here’s where this code is at on the internet. You go into this dev Swift folder. I’m not running it locally — or rather, I’m running it on a remote box, and we’re running it in a web browser here. Now we’re going to go to the Imagenette demo. So, if you can simply learn how to do this one notebook beginning to end, I think you’ll effectively understand the current state of the art for doing computer vision stuff, with Swift even. We don’t have to watch it all run, but this is all the same like I said. It’s free, it’s on the internet, you can download it. The videos will be released soon, and so I would highly suggest you check that out.
TensorFlow and Swift Repro (33:46)
Next, if you go through the TensorFlow / Swift repo — there’s a whole guide to how to download and install Swift for TensorFlow yourself. This is pretty easy to follow along, and they build nightly releases and stuff up here, so you can download it there. What we have here is swift codebase checked out on my computer. So, then you need to know basically two commands — this command:./swift/utils/update-checkout --clone --scheme tensorflow, which gives you the most recent check out for the Swift for TensorFlow source, and then this command: ./swift/utils/build-toolchain-tensorflow -g, which will then build you a fully functioning toolchain. So, you can combine these two together to build the whole Swift for TensorFlow codebase — it takes a little while to run, but then all the code is in here somewhere. So, you can go in here, modify it, and make a PR.
TensorFlow and Swift Models (34:52)
Then, the next thing I suggest you do is to mess around with this TensorFlow / Swift-models repository. They have a number of different examples in here, but we’ll look at the MNIST one. We’re going to run the MNIST demo again…but we’re running it in the cloud — well, on my computer remotely. Everything we did in the code lab earlier, but just in the command line. They have a number of different demos in here, I would highly suggest you play around with all these. There are a number of interesting tricks in this repository.
Here’s the guide for the build instructions, how to get your system set up, but I think you can all follow that. Hopefully, if you can do all that, you can make a pull request and you can start to contribute to the project. After that, I would tell you to start reading papers of other people’s code, and most importantly, get out into the real world and find a problem that nobody else has gone after and start trying to tackle it yourself, and then if you can, please try to share your knowledge. It can be as simple as writing a blog post, you can give a talk someplace, or you can simply find somebody else who is interested in this field and try to mentor them, however they need help.
Final Thoughts (37:50)
If you want to build a ship, don’t drum up the men to gather wood, divide the work, and give orders. Instead, teach them to yearn for the vast and endless sea. — Antoine
Very broadly, I like this quote — it’s by Antoine. He probably actually never said this, because he mostly wrote in French. But somebody took some creative liberties in translating his quote, so we’ll thank that person, whoever they are. But it’s a good quote. Like I said in the beginning, I believe in all this stuff. On one level, I can contribute code to these projects. On another level, I can stand up here and give presentations and try to get you closer to where I think you need to be. But ideally, I would teach you all to yearn for the sea, so to speak.
Here’s my attempt to do so. I think progress in general comes from the combination of hardware and software working together. If you look at the original iPhone, it was honestly not that advanced of a phone. There was literally nothing it did that other phones of its day couldn’t do as well. If you look at the software of the original iPhone, it was also pretty primitive by modern standards. But the combination of those two things together literally changed the world, and it’s literally why we’re sitting here today.
People have been building computers to essentially play video games for the past 50 years, and in the last decade or so, we’ve figured out ways to harness even just a tiny fraction of that power in order to solve a whole new set of problems that we’ve never even seen before. So, when the original iPhone came out, I saw it and thought, “This. This is what I should be doing, this is what I should be working on.” Deep learning came out, and once again, I heard that siren’s call — so that’s what I’ve been working on for the last few years. I think that because you all are doing Swift, and I think the whole world is moving to this — I think basically, this is an opportunity that’s ready-made for all of you. You should seize it, if possible. I would ask you to come work on all this stuff and help build the future of machine learning, and by extension, make the world move faster. Thank you for your time.
P.S. Thank you to Zhaolong Zhong for giving feedback on this speech!